context/experience/商品发放-钱包选择问题.md
我的实践:基于工具架构的知识复合
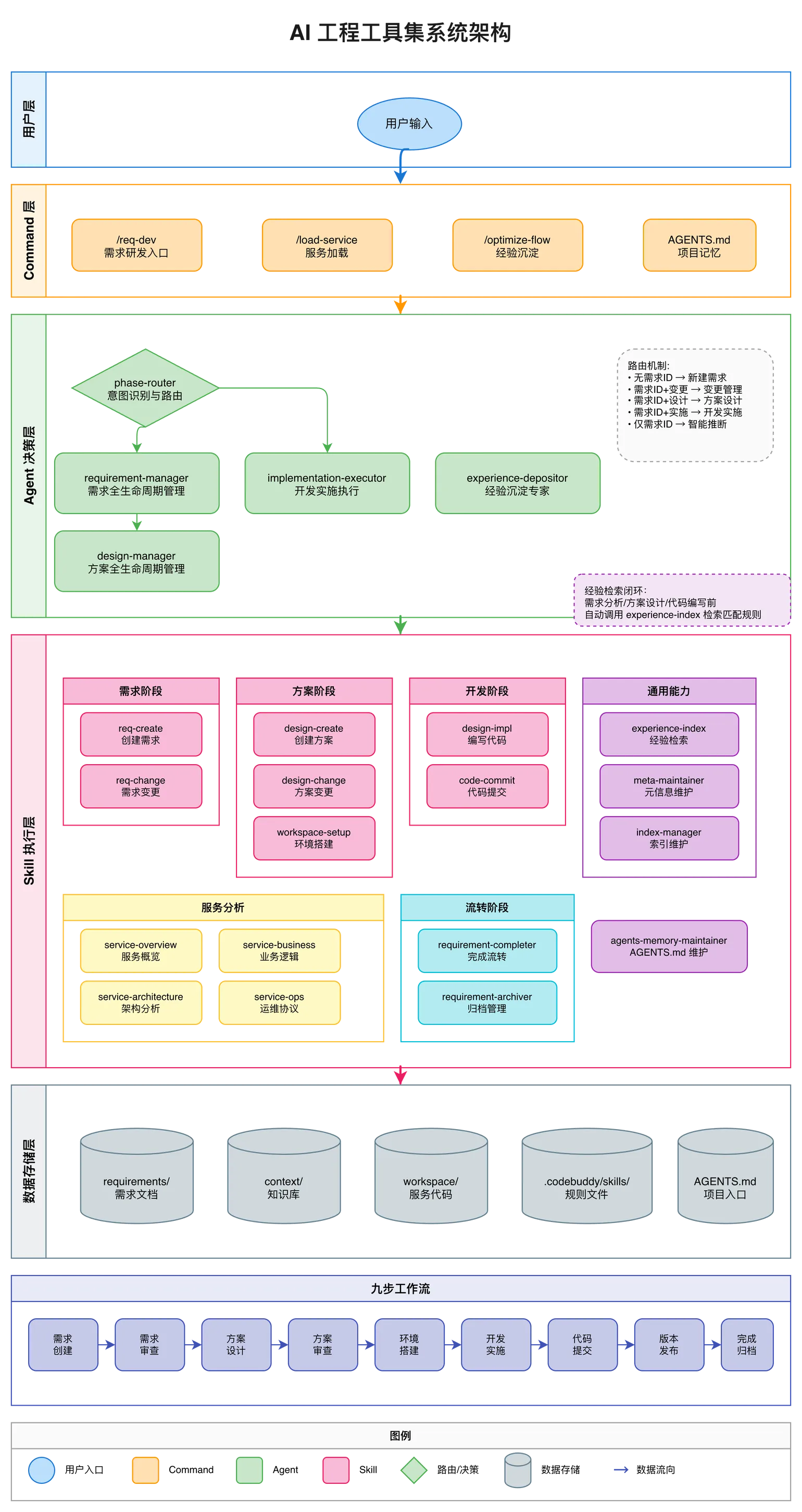
基于复合工程理念,我设计了一套 AI 工程工具架构来实现知识的持续沉淀与复用:
工具架构:
用户输入 → Command(入口)→ Agent(决策层)→ Skill(执行层)
↓
意图识别、流程路由
↓
调用具体 Skill 执行
↓
experience-index(经验检索)
- Command:用户交互入口,如
/req-dev、/optimize-flow - Agent:自主决策,智能判断意图,可调用多个 Skill
- Skill:固化流程,执行具体操作步骤
知识复合的两条路径:
路径 1:经验沉淀(/optimize-flow)
用户发现规律 → experience-depositor Agent → 识别规则类型 → 写入规则文件
↓
context-rules.md(上下文映射)
risk-rules.md(风险识别)
service-rules.md(服务补全)
pattern-rules.md(代码模式)
路径 2:经验检索(experience-index Skill)
需求分析/方案设计/代码编写前 → 自动检索匹配规则 → 加载相关 Context、提示风险、建议服务
复利效应示例:
第 1 次做支付需求:45 分钟(边做边踩坑)
↓ 沉淀规则:/optimize-flow "支付需求要加载 payment-service.md 并提示资金安全"
第 2 次做支付需求:15 分钟(experience-index 自动加载背景、提示风险)
↓ 沉淀更多规则:错误处理模式、服务依赖关系
第 N 次做支付需求:5 分钟(系统已积累完整的支付领域知识)
与传统文档的本质区别:
传统文档:写完没人看,看了也找不到对的时机
AI 工程化:experience-index 在正确的时刻自动检索,主动推送给 Agent
这就是为什么"知识应该沉淀到工具"不是一句口号,而是有实际 ROI 的工程决策。
对长期任务工程设计的启示
Compound Engineering Plugin 为 AI 工程化提供了极好的参考蓝图:
| 维度 | 启示 |
|---|---|
| 任务分解 | 阶段化执行(Plan → Work → Review → Compound),并行化处理,状态持久化 |
| 质量保障 | 多角度并行审查,分级处理(P1/P2/P3),持续验证(边做边测) |
| 知识管理 | 即时文档化(趁上下文新鲜),分类存储(按问题类型),交叉引用(关联 Issue、PR) |
| 工具设计 | 工具提供能力而非行为,Prompt 定义意图和流程,让代理决定如何达成目标 |
产品极简主义:不是"越来越丰富",而是"越来越纯粹"。每一代模型发布,工具都会变得更简单,因为复杂性转移到了模型内部。
这个理念深刻影响了我做 AI 工程化的设计思路:
-
入口极简化:整个系统只有两个命令入口——
/req-dev和/optimize-flow。不是因为功能少,而是把复杂性藏到了 Agent 的智能路由里。用户不需要记住十几个命令,只需要表达意图,Agent 会判断该调用哪个 Skill。 -
Skill 而非工具堆叠:speckit/openspec 倾向于提供更多工具、更多模板、更多约束。我选择相反的方向——把能力编码为 Skill,让 Agent 在需要时自动调用,而不是让用户手动选择"现在该用哪个工具"。
-
上下文自动加载:Claude Code 团队说"人类和 AI 看同样的输出,说同样的语言,共享同一个现实"。我把这个原则应用到上下文管理——不是让用户手动指定"加载哪些背景资料",而是让 Agent 根据当前阶段自动加载相关的 context/。用户感受不到"上下文加载"这个动作,但 AI 已经具备了完整的信息。
-
删除优先于添加:每次迭代时,我会问自己"有哪些东西可以删掉?"而不是"还能加什么功能?"。AGENTS.md 从最初的长篇大论,精简到现在只放通用规范和目录指针,具体流程全部下沉到 Skill 里。
-
双重用户设计:Claude Code 为工程师和模型同时设计界面。AI 工程化也是——
/req-dev命令人可以手动调用,Agent 也可以在流程中自动调用子 Skill。同一套能力,两种调用方式,没有冗余。
当前实践的目标:让工具尽可能"隐形"——用户只需要说"我要做一个商品发放需求",系统自动加载上下文、自动识别阶段、自动调用对应 Skill、自动沉淀经验。用户感受不到在"使用工具",只是在"完成工作"。
5.3 目录结构:位置即语义
your-project/
├── AGENTS.md # 项目记忆入口(每次会话自动加载)
├── .codebuddy/ # AI 自动化配置
│ ├── agents/ # Agent 定义(决策层)
│ ├── commands/ # 命令入口
│ └── skills/ # Skill 定义(执行层)
├── context/ # 项目知识库(长期记忆)
│ ├── business/ # 业务领域知识
│ ├── tech/ # 技术背景
│ │ └── services/ # 服务分析文档
│ └── experience/ # 历史经验
├── requirements/ # 需求管理
│ ├── INDEX.md # 需求索引
│ ├── in-progress/ # 进行中需求
│ └── completed/ # 已完成需求
└── workspace/ # 代码工作区(Git 忽略)
三个核心约束:
- 入口短小:AGENTS.md 只放通用规范 + 目录指针,不写具体流程步骤
- 位置即语义:requirements/ 放需求产物,context/ 放可复用上下文,workspace/ 放代码
- 复利沉淀:每次执行命令,除了产出当前结果,还要让"下一次更快、更稳"
5.4 经验沉淀的技术实现
前面 4.1 节讲了复合工程的理念和三层沉淀机制,这里聚焦具体怎么实现。
触发时机:什么时候沉淀?
不是:做完需求后专门花时间"写总结"
而是:在流程关键节点自动触发沉淀
具体触发点:
├── 需求完成时 → requirement-completer skill 自动提取可复用经验
├── 遇到问题解决后 → 用户说"记住这个坑" → experience-depositor agent 记录
├── 代码提交时 → code-commit skill 检查是否有值得记录的模式
└── 流程优化时 → /optimize-flow 命令专门用于沉淀和优化
沉淀格式:记录什么?
# context/experience/商品发放-钱包选择问题.md
## 问题描述
商品发放时选错钱包类型,导致用户领取失败
## 触发条件
- 需求涉及商品发放
- 商品类型为虚拟商品
## 解决方案
虚拟商品必须发到虚拟钱包,实物商品发到实物钱包
具体判断逻辑见 Apollo 配置:xxx.wallet.type
## 校验方式
检查 goods_type 与 wallet_type 的匹配关系
## 关联文档
- context/tech/Apollo配置规范.md
- context/tech/services/商品服务技术总结.md
检索机制:怎么在对的时候加载?
检索由 experience-index Skill 统一负责,在需求分析、方案设计、代码编写前自动调用:
Agent 的上下文加载逻辑:
1. 意图识别阶段
phase-router 识别意图,路由到对应 Agent
↓
2. 经验检索阶段
Agent 调用 experience-index Skill,传入场景描述
Skill 检索四类规则文件:
├── context-rules.md → 匹配需加载的背景文档
├── risk-rules.md → 匹配风险提示
├── service-rules.md → 匹配服务依赖建议
└── pattern-rules.md → 匹配代码规范
↓
3. 返回结构化结果
{
"context": { "files": ["商品发放历史问题.md"] },
"risk": { "alerts": [{"level": "high", "message": "注意钱包类型"}] },
"service": { "suggestions": ["商品服务", "钱包服务"] },
"pattern": { "files": ["error-handling.md"] }
}
↓
4. Agent 主动提醒
"注意:历史上商品发放有钱包选择问题,请确认..."
规则沉淀入口:通过 /optimize-flow 命令,调用 experience-depositor Agent 将新规则写入对应规则文件。
演进路径:从文档到 Skill 到 Command
阶段 1:纯文档(被动)
context/experience/xxx.md
→ AI 读取后提醒,但需要人确认
阶段 2:校验 Skill(半自动)
skill/product-distribution-validator
→ 自动校验配置,发现问题直接报错
阶段 3:完整 Command(全自动)
cmd/implement-product-distribution
→ 一个命令:加载背景 + 校验 + 生成 + 提醒 + 沉淀新经验
演进判断标准:
- 同类需求做了 5 次以上 → 考虑封装 Skill
- Skill 被调用 10 次以上 → 考虑封装 Command
- 不要过早抽象,让实践驱动演进
与 speckit 的本质区别
speckit 的知识流向:
人脑 → Spec 文档 → 代码
↑__________|
下次还要从人脑开始
AI 工程化的知识流向:
人脑 → context/ → Skill → Command
↑_________|________|
知识留在工具链里,下次直接复用
5.5 时间成本的量化对比
前面 2.5 节从"问题-方案"角度做了概念对比,这里从时间成本角度量化差异:
| 执行次数 | speckit/openspec | AI 工程化 | 累计节省 |
|---|---|---|---|
| 第 1 次 | 45 分钟 | 45 分钟(建立 context/) | 0 |
| 第 2 次 | 45 分钟(人重新想) | 15 分钟(部分复用) | 30 分钟 |
| 第 5 次 | 45 分钟(还是要想) | 5 分钟(大量复用) | 130 分钟 |
| 第 10 次 | 45 分钟(…) | 3 分钟(高度自动化) | 315 分钟 |
关键差异:
- 知识位置:speckit 在人脑(每次想),AI 工程化在 context/+skill/
- 新人上手:speckit 依赖老人传授,AI 工程化第一天就能用
- 边际成本:speckit 恒定,AI 工程化递减