Karpathy: 知识库会随着每次 LLM 的查询和整理而自行生长,而不是静态存储
这两天 karpathy 的"知识编辑"言论火了,我觉得他说的最重要一点就是自进化!
巧合的是,我刚好也在做同样的事情。随着知识膨胀的速度越来越快,我发现现有的工具根本无法跟上膨胀的速度。
所以,我做了一个自己的知识库项目,BookAnything。
目前已实现知识整理和结构化,正在探索知识的自进化和自探索能力~
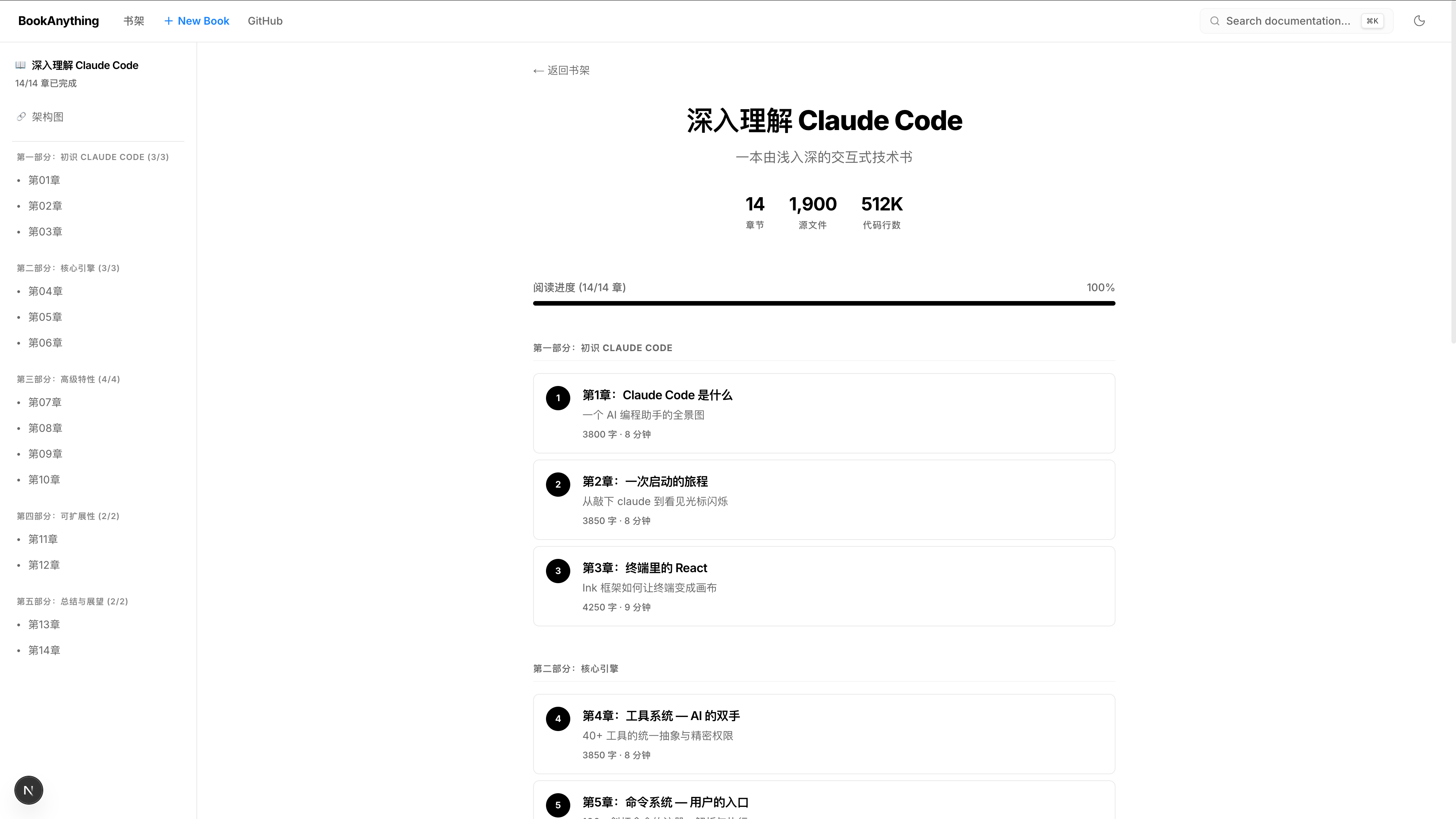
这就是 BookAnything 初版的样子,我也在用它来系统性学习一些理论(项目名称改成 WikiAnything 会不会更吸引人?)
我的困境其实有 2 个:
- Agent 时代,知识更新迭代太快了,我想快速了解某个最新的库的原理、架构等
- 知识的终点是应用:基于已 archived 的知识库,探索我当前开发项目上的最优解法(至少给我个灵感hh)
另外我想围绕着新知识构建快速构建、检索、思考、研究等能力的工具,并且随着知识膨胀,支持自进化。
现在正在攻坚自进化。 除了基于 AST 和 DIFF 来实现,我理解的自进化,应该要根据所有已有的知识库,去探索出新的能力并自动写一个知识库出来。
从一些现有就像看论文一样,看多了就会有想法。我需要这个想法自动跳出来,最好是结合业务!