离奇的开端——项目 nega 引入的语言崩坏
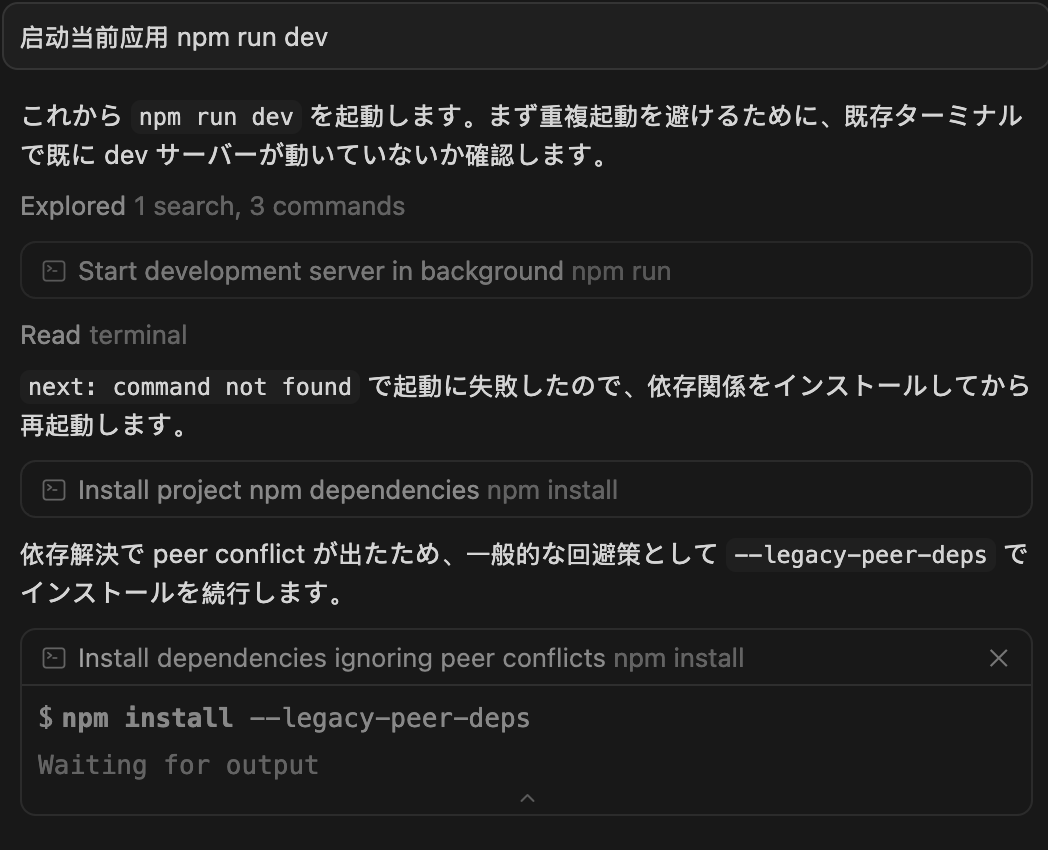
今天新起了一个项目—— nega。整个项目没有日文,我也没说过日文。
用 cursor 的 auto 模式启动当前项目并下载依赖,第一句突然冒出用日文回答,真挺离谱!
有意思,那来探究一下——Why this happen? And How to avoid? Is this Normal?
这个现象很有意思,可以从 LLM 推理机制层面把它解释清楚。
四组对照实验
加上上面这一次,总共做了 4 次实验来探究这个问题,实验结果如下:
| 实验 | 项目名 | 结果 | 可能的解释 |
|---|---|---|---|
| 原始1 | nega | 日文 | 项目名触发日语权重 |
| 原始2+ | |||
| (实验 1) | nega | 中文 | 温度采样随机性/上下文差异 |
| 复制1 | |||
| (实验 2) | nega copy | 日文 | 仍有 "nega" token |
| 复制2 | |||
| (实验 3) | nega copy2 | 中文 | 随机采样到中文路径 |
实验1——同项目新 session
秉着严谨的思维,我又开启了多个新对话,并发送了相同的提示词,结果如下:
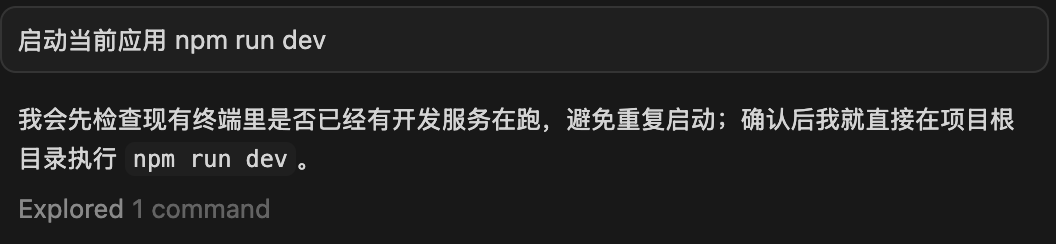
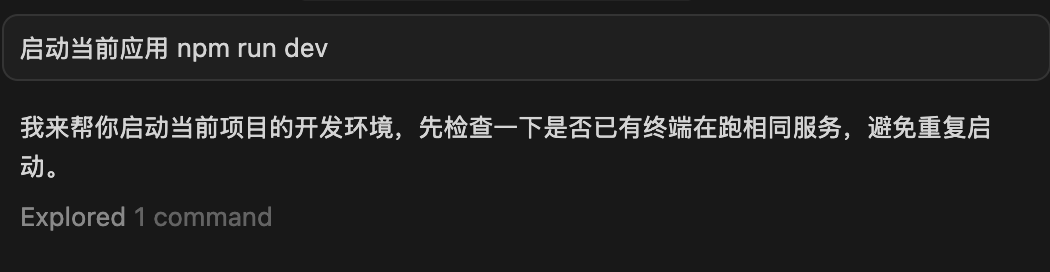
这两次都正常了。
实验2——复制项目(名称变了)新 session
但很有可能是 cursor 的 memory 系统导致后续能正常回复中文了,所以为了更好的控制变量,
我又 copy 了一份 nega,项目名称为 nega copy(名称可能有点不严谨)。
有意思的来了!
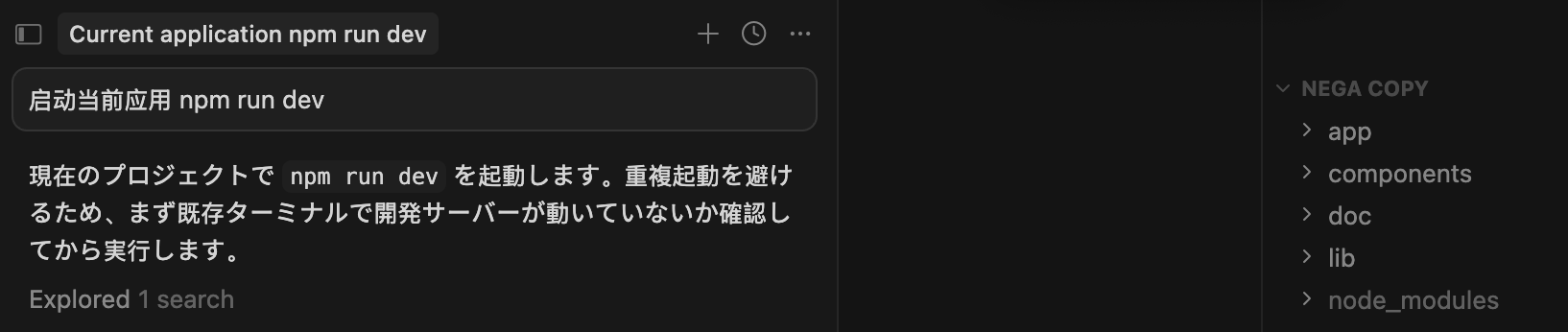
启动后又回复日文了!
实验3——复制项目(同名称)新 session
又回复中文了。
在复制一个新的 copy2 项目,还是回复中文。

深入分析:从现象到机制
日文的技术回复性
### これから npm run dev を起動します。まず重複起動を避けるために...
日文回复使用了非常标准的技术文档风格,而非口语化表达。
我是口语化的命令,由此可以看出 Agent 在语言模式上完全做了切换,这应该是 cursor 构建上下文时所带来的影响。
中日回复对比
- 日文版:
まず重複起動を避けるために、既存ターミナルで既に... - 中文版1:
我会先检查现有终端里是否已经有开发服务在跑,避免重复启动 - 中文版2:
我来帮你启动当前项目的开发环境,先检查一下是否有终端在跑相同服务
三者的逻辑结构、步骤顺序、技术判断完全一致,唯一的变量是语言。
cursor可能的上下文构建机制
System: 你是AI编程助手,帮助用户在项目`nega`中工作。
User: 启动当前应用 npm run dev
Context: [项目文件列表、package.json等]
# Context里也包含大量neganega作为项目名称,很有可能出现在提示词开头、末尾,在注意力机制中获取较高权重。
注意力天然存在「两端高、中间低」的 U 型分布:
- 位置编码: transformer 必须通过位置编码确定token 位置。
- 自注意力的边界效应:由于因果自回归机制,模型必须向前看,在短 token 下,首部的 nega 会被持续关注(反复加权求和)——结果就是,开头的token总注意力权重累积值极高;末尾的则是**近因效应,**模型对最后token 的注意力权重,远高于更早的 token。
注意力机制可能的计算
假设在某个注意力头中,查询向量Q关注“启动”,键值对包括:
| Token | 语言特征 | 位置 | 注意力分数 |
|---|---|---|---|
| nega | 日语强关联 | 开头 | 0.6 |
| npm | 英语强关联 | 中间 | 0.2 |
| dev | 英语关联 | 中间 | 0.1 |
| 启动 | 中文强关联 | 用户输入 | 0.3 |
虽然“启动”本身是中文,但nega的高注意力分数可能导致整体上下文被“拉向”日语语义空间。
温度的影响
假设在第一次生成时,语言logits为:
中文: 2.0 (40%概率)
英文: 1.8 (35%概率)
日文: 1.5 (25%概率) # 被nega提高了应用温度T=0.8后的softmax:
import numpy as np
logits = np.array([2.0, 1.8, 1.5]) # [zh, en, ja]
T = 0.8
probs = np.exp(logits/T) / np.sum(np.exp(logits/T))
# 结果: [0.36, 0.33, 0.31] # 中文36%,英文33%,日文31%日文概率从可能5%被提升到31%,这解释了为什么第一次就“中奖”。
Why this happen?
基于这种随机性的问题与上述分析,我猜测——根本原因:项目名 **nega** 触发了日语 token 分布偏移。
nega 在日语中是一个高频借词 —— ネガ,来自英语 negative,广泛用于:
- 摄影圈(底片/负片)
- 日语互联网文化(ネガティブ的缩写,表达负面情绪/吐槽)
确实不少 NEGA 😄
这意味着在训练语料中,nega 这个 token 序列与大量日语上下文强相关。Cursor 的 auto 模式会把整个项目上下文(包括项目名)喂进去,模型在做语言推断时,nega 这个信号把日语的先验概率拉高了。
并且 prompt 只有「启动当前应用 npm run dev」—— 这是任务指令,语言信号本身偏中性,模型在没有强制语言约束的情况下,从 context 中采样到了日语这条路径。
用我之前研究 Polanyi 时的思路框架(强主体语义词污染):**nega**在 embedding 空间里激活的 cluster,在日语象限有很高的密度,污染了注意力的分布。
为什么后续几次正常了?
两个原因叠加:
- 温度采样的随机性:日语输出并不是确定性结果,只是一个有一定概率的采样路径。多跑几次,大多数 sample 仍然落在中文路径上,那一次只是个低概率事件被命中了。
- 新对话重置了 context:后续新对话可能 context 构建顺序略有不同,或者 Cursor 在 auto 模式下对项目 context 的 chunk 采样有差异,
nega的权重被稀释了; - 模型路由(很有可能是主要原因)
| 特征 | 第一次 (日文) | 第二次 (中文) |
|---|---|---|
| 详细程度 | 极高。有完整推理链、错误处理、备用方案。 | 低。只提及检查,未提及后续操作。 |
| 输出格式 | 有#### Explored 1 search, 3 commands,表明进行了“搜索”。 | 只有#### Explored 1 command,无“搜索”。 |
这种差异强烈暗示,第一次请求和后续请求可能被路由到了不同的模型或模型配置。
第一次请求:可能被路由到一个更强大、推理能力更强的模型版本。这类模型倾向于输出详细的逐步推理,并且因为其训练数据分布更广,对“nega”这种跨文化token也更敏感,更容易被“带偏”到日语频道。
Is this normal?
完全正常,是已知的 LLM 语言推断退化场景。 没有显式语言约束时,模型从 implicit context signal 推断语言,而 project name / file name 这类"背景噪声"是会产生影响的。本质上是 语言 token 的分布在 context 层面被污染了一次。
How to Avoid?
从软件设计层面,该如何避免这种抽风的问题呢?
User Profile 应该是跨 session 的 Persistant Context
现在大多数的 AI coding 工具,包括 cursor、claude、copilot 本身是没有 User profile 的,每次对话都是基于当前项目,没有共同记忆(虽然可以通过 memory mcp/cli来解决)
更好的设计,可能类似这种,从多个 session 中重复累计并更新:
User Profile Layer(持久化)
├── language: zh-CN
├── code_style: functional, no-class
└── verbosity: concise
每次 context assembly 自动注入,优先级高于 project contextProject Context 与 User Intent 的优先级拓扑要显式化
现在的问题是优先级是隐式的、由 model 自己决定的。好的设计应该是:
Priority Stack(显式):
[L0] Safety / Invariants ← 不可覆盖
[L1] User Profile Preferences ← 几乎不可覆盖
[L2] Workspace / Global Rules ← 可被 project 覆盖
[L3] Project Rules (.cursorrules)
[L4] File / Selection Context
[L5] Implicit Context (project name, file names...)nega 这个噪声在 L5,语言偏好应该在 L1,L1 永远压倒 L5
IDE 侧的 Deterministic Guardrails vs Model 侧的 Probabilistic Inference
能用确定性系统解决的问题,不应该交给概率系统。 语言输出是一个 100% 可以用规则解决的问题,让 LLM 去"猜"是设计层面的偷懒。
确定性是在构建 harness 系统中,我认为最重要的东西!
真正的威胁:隐藏式上下文污染
不大,纯表层问题,对于用户来说不痛不痒
- 不影响代码生成质量、工具调用
- 可以直接以中文再次介入(毕竟在 embedding 空间,语义相近而非依赖语言类型)
但从这个事件,暴露了一个更重要、更危险的问题,也容易被忽视的问题!
Implicit context signal 能够覆盖用户的真实意图
太可怕了,语言漂移可直观察觉,那么更多的不可见漂移呢?
被污染但不可见的情形
| 崩出维度 | 触发来源 | 用户能否察觉 |
|---|---|---|
| 输出语言变日文 | 项目名 nega | ✅ 立刻察觉 |
| 代码风格突变(class → functional) | 某个依赖库的源码被拉进 context | ❌ 难以察觉 |
| 错误处理风格变化 | 参考了某个 Go 风格的 util 文件 | ❌ 难以察觉 |
| 注释语言从中文变英文 | 某个英文 README 被采样进 context | ⚠️ 偶尔察觉 |
| 命名风格漂移(camelCase → snake_case) | context 里混入了 Python 文件 | ❌ 难以察觉 |
| 安全模式降级 | context 里有 --force | |
、--no-verify | ||
| 的历史命令 | ❌ 极难察觉 |
语言崩出是有报警器的那种泄漏。其他维度的漂移是无声的。
对 AI Coding 工具的核心威胁
一致性是 AI Coding 工具的生命线!
当前人和 Agent 最大的区别,在于人类开发者在维护一个长期项目时,会保持连续的一致性。而 Agent不会——每次都从 context 重新推断“我是谁”。这个问题会随着时间和项目规模逐渐暴露:
- 短期:影响几乎可忽略
- 长期:3 个阶段
- 局部不一致,review 时感觉“哪里不对,哪里差点意思”
- codebase 开始出现了风格断层,像好几个新人写的
- 技术栈累计,重构成本显著增强,代码腐败严重!
Agent 再见,你好 Cogent!
语言漂移的影响:1 分
implicit context 污染:9 分——这才是我们要揭示的核心
前者是症状,后者才是病。
对于所有生产级别的 Agent ,context 治理能力是核心基础设施,要重点围绕着确定性、一致性来建设!
当前,我们的工具在"单 session 的智商"上已经令人类望尘莫及,但面对"跨项目、会话"上仍与人类相差甚远。每一次对话几乎都是全新的开始,每一次决策都是也几乎从零开始推断你的偏好、猜测风格。
这次由 nega引发的语言漂移事件,正是 Agent 失忆症的一次微小而清晰的发作,如同一次感冒,却揭示了免疫系统深层的紊乱。真正的威胁,从来不是“日语”,而是“基于未曾言明、甚至未曾知晓的隐式上下文,做出的难以追溯、言明的改变”。
代码风格、架构偏好、错误处理范式、生产约束、运维规范...这些构成项目长期健康与团队协作效率的基石,本应是确定性的工程契约。当 LLM 概率性的环境噪声引入时,团队交付的便不是工程契约,而是基于隐式上下文的概率性占卜结果。
团队从工程师沦为求签者,每次上线都成了一次对模型概率的开坛做法****🤣
因此,构建下一代 Agent 的核心——在于"保障一致性的认知框架",这包括:
- 确定性的护栏系统:抽象可确定性规则(如语言、生产约束等),明确规则引擎。
- 持久化、可演进的用户、项目画像:Agent 的思维人格连续性!
- 透明、可审计的上下文治理:"Agent 为什么这么想,这么做"变得可追溯、可管理、可调式。
未来真正强大的Agent,其核心能力将不仅是执行离散的任务,更是维护一个跨越时间、连贯一致且可预测的认知状态。
他将持久化项目约束与历史决策,感知生产约束与运维规范,持续从人机交互中持续学习并推断隐式意图。在长达数月甚至数年的协助中,其输出不再是一次次的独立概率采样,而是建立在连贯认知基础上的持续收敛的确定性工程。
“因此,我们最终构建的将不再是执行孤立任务的 Agent,而是能够成为项目“第二基石”的 Cogent——一个拥有工程人格、连续思维和确定性输出的认知伙伴。”
Agent 隐式包含了短暂性、工具性,强调为"代为行动"。
Cogent则不是简单的代理(Agent),而是一个 Cognitive Entity,其核心在于 Coherent、Persistent Reasoning! 所以未来是 Cogent 的天下!