在构建 repo 的上下文管理系统时,选型落在了三级级联 CLAUDE.md 与 root-CLAUDE.md + .claude/rule 上了。官方文档说——级联 CLAUDE.md 与 rule均支持渐进式触发载入。我就有点好奇,真的是这样么?那么就引入了 3个问题:
- 如何通过 CLAUDE 机制实现加载的可观测性?
- path-scoped rule与级联 CLAUDE.md 的按需加载是否真实有效?
- rule 和 级联 CLAUDE.md 的触发原理是什么?有什么区别?
如何通过 CLAUDE 机制实现加载的可观测性?
基于 Hook - InstructionsLoaded 实现原生的加载可观测性
组件清单
.claude/
├── settings.json # ① Hook 注册
└── hooks/
├── instructions-observer.sh # ② 数据采集器
└── view-instructions-log.sh # ③ 日志查看器
/tmp/
├── claude-instructions-load.jsonl # ④ 原始数据(JSONL)
└── claude-instructions-summary.log # ⑤ 人读摘要设计原理
① Hook 注册(settings.json)
"InstructionsLoaded": [
{
"hooks": [{
"type": "command",
"command": "bash .claude/hooks/instructions-observer.sh",
"timeout": 5
}]
}
]InstructionsLoaded 是 Claude Code 原生 hook 事件:每当一条 CLAUDE.md 或 rule 文件被加载到上下文时触发。hook 通过 stdin 接收 JSON 事件数据。
关键特性:
- 每条规则独立触发一次,不是批量数组
- hook 是观测性质(post-load),无法阻止加载
- timeout 5 秒,不影响主流程性能
② 数据采集器(instructions-observer.sh)
stdin JSON → python3 解析 → 写两份日志输入格式(Claude Code 提供,每次一个 JSON 对象):
{
"session_id": "61da82e1-...",
"hook_event_name": "InstructionsLoaded",
"cwd": "/path/to/project",
"file_path": "/abs/path/.claude/rules/service-layer.md",
"memory_type": "Project",
"load_reason": "path_glob_match",
"globs": ["internal/service/**/*.go"],
"trigger_file_path": "/abs/path/internal/service/evidence_agent.go"
}关键字段:
| 字段 | 含义 |
|---|---|
load_reason | 加载原因:session_start(启动即加载)、path_glob_match(按需匹配)、nested_traversal(子目录 CLAUDE.md)、include(@path 导入)、compact(/compact 后重载) |
file_path | 被加载的规则文件绝对路径 |
globs | 触发匹配的 glob 模式列表(仅 path_glob_match) |
trigger_file_path | 触发加载的源文件(仅 path_glob_match)— 即 Claude 正在 Read 的文件 |
输出:
- JSONL 日志(
/tmp/claude-instructions-load.jsonl):每行一个完整 JSON,附加_ts时间戳。JSONL 格式保证多条并发写入不会粘连。 - 摘要日志(
/tmp/claude-instructions-summary.log):一行一条,人读友好格式:
2026-03-31 18:00:13 path_glob_match .claude/rules/service-layer.md ['internal/service/**/*.go'] <- internal/service/policy/arbiter.go路径缩短:绝对路径自动去掉 cwd 前缀,转为相对路径,提高可读性。
③ 日志查看器(view-instructions-log.sh)
四种模式:
| 命令 | 作用 |
|---|---|
bash .claude/hooks/view-instructions-log.sh | 时间线摘要 |
bash .claude/hooks/view-instructions-log.sh --stats | 按 reason/file 聚合统计 |
bash .claude/hooks/view-instructions-log.sh --raw | 原始 JSON 美化输出 |
bash .claude/hooks/view-instructions-log.sh --clear | 清空所有日志 |
--stats 输出示例:
Total loads: 8
=== By Reason ===
6 path_glob_match
2 session_start
=== By File ===
2 .claude/rules/internal-nav.md
1 .claude/rules/service-layer.md
1 .claude/rules/pkg-layer.md
1 .claude/rules/cmd-layer.md
1 .claude/rules/prompts-layer.md
1 .claude/rules/tools-layer.md数据流
Claude Read("internal/service/foo.go")
│
▼
Claude Code 内部: glob 匹配 "internal/service/**/*.go"
│
▼
匹配成功 → 加载 .claude/rules/service-layer.md 到上下文
│
▼
触发 InstructionsLoaded hook → stdin 传入 JSON
│
▼
instructions-observer.sh
├── → /tmp/claude-instructions-load.jsonl (JSONL 原始记录)
└── → /tmp/claude-instructions-summary.log (一行摘要)
│
▼
view-instructions-log.sh 读取日志 → 展示/统计path-scoped rule与级联 CLAUDE.md 的按需加载是否真实有效?
实验-1:path-scope load-in-need
- 在新对话构建 prompt,测试 rules 和 CLAUDE.md 的加载情况
▐▛███▜▌ Claude Code v2.1.78
▝▜█████▛▘ Opus 4.6 (1M context) · API Usage Billing
▘▘ ▝▝ ~/.cursor/worktrees/risk-engine-go__Workspace___SSH__kylinmiao-any11.devcloud.woa.com_/clq
⎿ SessionStart:startup hook error
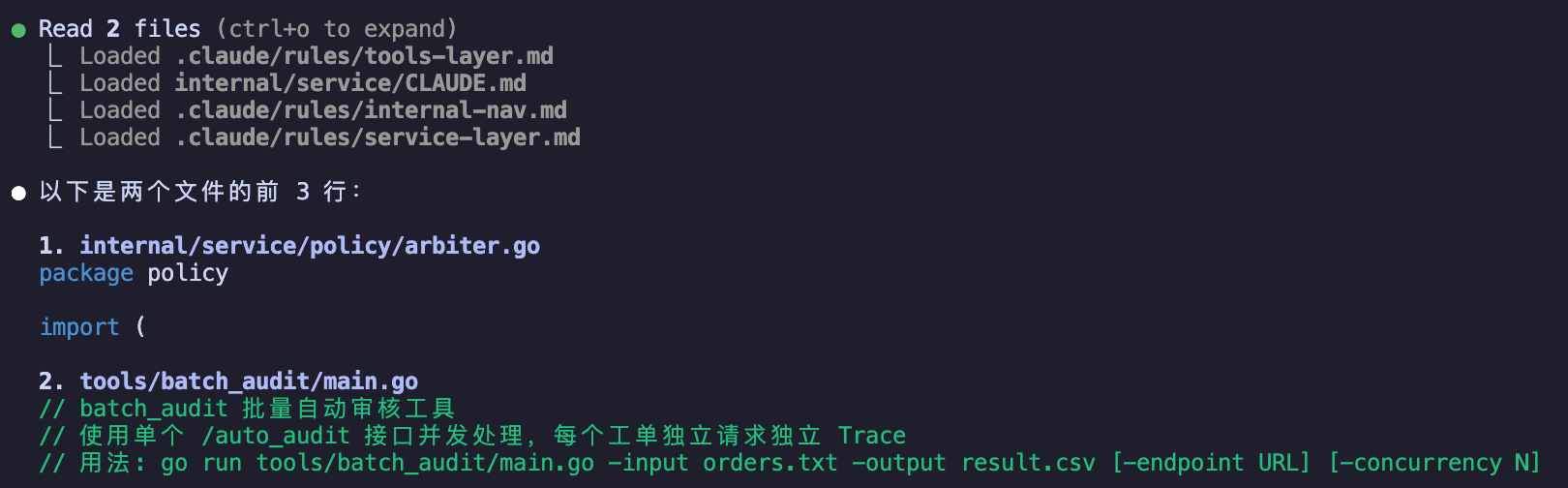
❯ 依次读取以下文件,每个读完后告诉我文件的前 3 行内容:
1. internal/service/policy/arbiter.go- 会话执行过程,可以看到加载了相关的 rule

关联 rule 的配置如下:
// internal-nav.md
---
paths:
- "internal/**/*.go"
---
# internal/ — Core Application Code Navigation
...
// service-layer.md
---
paths:
- "internal/service/**/*.go"
---
...- 跑"观测脚本",结果如下
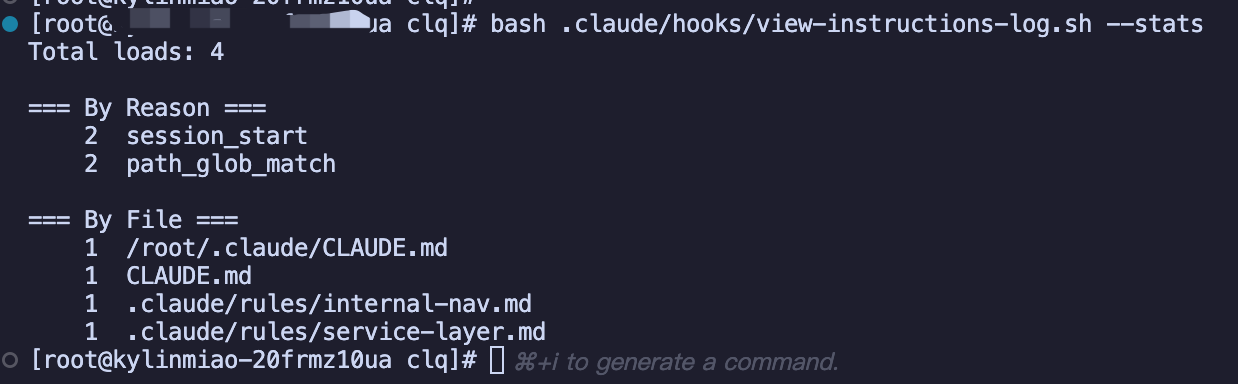
实验-2:级联 CLAUDE.md-in-need
结论:多轮测试发现,级联 CLAUDE.md 的载入非常不稳定!
并且 session_start 的行为有时候抓取不到
- 构建测试 prompt
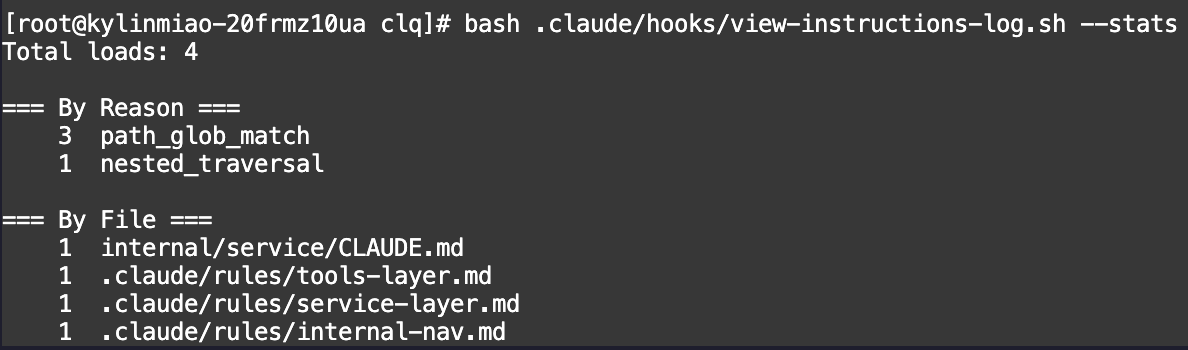
- 结果如下:稳定保证级联的 CLAUDE.md 被载入!
path_glob_match(rules)— ✅ 稳定
nested_traversal(级联 CLAUDE.md)— ✅ 稳定
rule 和 级联 CLAUDE.md 的触发原理是什么?有什么区别?
一、核心概念对比
| 特性 | Rules (path_glob_match) | 级联 CLAUDE.md (nested_traversal) |
|---|---|---|
| 触发机制 | Glob 模式匹配目标文件路径 | 目录树向上遍历,逐层发现 |
| 文件位置 | .claude/rules/*.md(含 paths: frontmatter) | 各级目录的 CLAUDE.md / .claude/CLAUDE.md |
| 适用范围 | 仅匹配 glob 的文件 | 该目录层级下的所有文件 |
| 加载条件 | 按需匹配(conditional) | 无条件加载(unconditional) |
| 核心库 | ignore 库(gitignore 兼容) | Node.js path.dirname() 循环 |
Rules 系统:path_glob_match 原理
定义方式
Rules 文件放在 .claude/rules/*.md,通过 YAML frontmatter 声明 glob 模式:
---
paths: |
src/api/**/*.ts
src/services/**/*.ts
---
这里是针对 API 文件的指令内容...有 paths: → 条件规则(conditional),只在 glob 匹配时加载
无 paths: → 无条件规则(unconditional),走 nested_traversal 加载
匹配流程
核心函数:processConditionedMdRules()(claudemd.ts)
1. 发现所有带 frontmatter 的 .claude/rules/*.md
2. 对每个规则文件:
a. 确定基准目录(base dir)
- Project rules → .claude 的父目录(即项目根)
- Managed/User rules → 原始 CWD
b. 计算相对路径
relativePath = path.relative(baseDir, targetFilePath)
c. 调用 ignore 库匹配
ignore().add(file.globs).ignores(relativePath)
d. 匹配成功 → 注入系统提示词,loadReason = 'path_glob_match'示例
规则:/project/.claude/rules/api.md → paths: src/api/**/*.ts
目标文件:/project/src/api/users.ts
base = /project
relative = src/api/users.ts
ignore().add(["src/api/**/*.ts"]).ignores("src/api/users.ts") → ✅ 匹配
目标文件:/project/src/ui/Button.tsx
relative = src/ui/Button.tsx
ignore().add(["src/api/**/*.ts"]).ignores("src/ui/Button.tsx") → ❌ 不匹配级联 CLAUDE.md 系统:nested_traversal 原理
核心算法
核心函数:getMemoryFiles()(claudemd.ts)
步骤 1:从 CWD 向上收集目录
/home/user/project/src/api
/home/user/project/src
/home/user/project
/home/user
/home
步骤 2:反转顺序(根 → CWD),依次处理
/home → 最先加载(最低优先级)
/home/user
/home/user/project
/home/user/project/src
/home/user/project/src/api → 最后加载(最高优先级)
步骤 3:每个目录加载以下文件
├── CLAUDE.md (项目指令)
├── .claude/CLAUDE.md (替代位置)
├── .claude/rules/*.md (无条件规则)
└── CLAUDE.local.md (私有本地指令)优先级原则:后加载 = 高优先级
优先级从低到高:
1. Managed(/etc/claude-code/) ← 始终加载
2. User(~/.claude/) ← 可通过 settings 禁用
3. 远端祖先目录的 CLAUDE.md ← 最先遍历到
4. 近端子目录的 CLAUDE.md ← 最后遍历到(覆盖远端)
5. CLAUDE.local.md ← 私有,优先级更高关键细节
- Settings 门控:所有加载受
isSettingSourceEnabled()控制 - Git Worktree 去重:检测嵌套 worktree,避免重复加载父仓库指令
- 缓存:
getMemoryFiles()使用 memoize,同会话内复用结果
两者如何协同工作
当访问一个目标文件(如 src/api/users.ts)时,加载分三阶段:
阶段 1:Managed & User 条件规则
→ 检查 /etc/claude-code/.claude/rules/ 和 ~/.claude/rules/
→ glob 匹配 → path_glob_match
阶段 2:嵌套目录指令(CWD 到目标文件之间的中间目录)
→ 加载 CLAUDE.md + 无条件规则 → nested_traversal
→ 加载条件规则并 glob 匹配 → path_glob_match
阶段 3:CWD 层级条件规则(根 → CWD 每层目录)
→ 仅加载条件规则并 glob 匹配 → path_glob_matchHook 事件中的三种 loadReason
这两个机制最终在 InstructionsLoaded hook 中通过 loadReason 区分:
const loadReason = memoryFile.globs
? 'path_glob_match' // 有 glob 模式且匹配成功
: memoryFile.parent
? 'include' // 通过 @include 指令引入
: 'nested_traversal' // 目录遍历时发现的无条件规则/CLAUDE.md| loadReason | 含义 | 典型文件 |
|---|---|---|
nested_traversal | 目录遍历过程中发现,无需 glob 匹配 | CLAUDE.md, 无 frontmatter 的 rules |
path_glob_match | 有 paths: frontmatter 且 glob 匹配目标文件 | 带条件的 .claude/rules/*.md |
include | 被其他文件通过 @./path.md 引入 | 任意被 @include 的 .md 文件 |
@include 子系统(补充)
CLAUDE.md 和 rules 文件都支持 @include 语法:
@./guidelines/base.md ← 相对路径
@~/shared/standards.md ← home 目录
@/etc/global-rules.md ← 绝对路径- 使用 Marked lexer 解析 markdown,跳过代码块和行内代码
- 最大递归深度 5 层,防止无限循环
- 通过
processedPathsSet 防止循环引用
一句话总结
path_glob_match是"按文件路径模式精准匹配"——只有 glob 命中的文件才加载对应规则;nested_traversal是"沿目录树向上遍历逐层发现"——越靠近工作目录的指令优先级越高,无需匹配,对该层级所有文件生效。 两者协同工作,通过三阶段加载流程为 Claude 提供从全局到文件级别的分层指令。
附录:关键源码文件
| 文件 | 职责 | 核心函数 |
|---|---|---|
src/utils/claudemd.ts | 主要编排逻辑 | getMemoryFiles(), processMdRules(), processMemoryFile(), processConditionedMdRules() |
src/utils/attachments.ts | 集成入口 | getConditionalRulesForFile(), memoryFilesToAttachments() |
src/utils/hooks.ts | Hook 触发 | executeInstructionsLoadedHooks() |